Bu sayfada Metrik sözlüğü terimleri yer almaktadır. Tüm sözlük terimleri için burayı tıklayın.
A
doğruluk
Doğru sınıflandırma tahminlerinin sayısının toplam tahmin sayısına bölünmesiyle elde edilir. Yani:
Örneğin, 40 doğru ve 10 yanlış tahminde bulunan bir modelin doğruluğu şu şekilde olur:
İkili sınıflandırma, doğru tahminler ve yanlış tahminler kategorileri için belirli adlar sağlar. Bu nedenle, ikili sınıflandırma için doğruluk formülü aşağıdaki gibidir:
Bu örnekte:
- TP, doğru pozitif (doğru tahminler) sayısıdır.
- TN, doğru negatiflerin (doğru tahminler) sayısıdır.
- FP, yanlış pozitiflerin (yanlış tahminler) sayısıdır.
- FN, yanlış negatiflerin (hatalı tahminler) sayısıdır.
Doğruluğu hassasiyet ve geri çağırma ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler bölümüne bakın.
PR eğrisinin altındaki alan
PR AUC (PR Eğrisinin Altındaki Alan) başlıklı makaleyi inceleyin.
ROC eğrisinin altındaki alan
AUC (ROC eğrisinin altındaki alan) bölümüne bakın.
AUC (ROC eğrisinin altındaki alan)
İkili sınıflandırma modelinin pozitif sınıfları negatif sınıflardan ayırma becerisini gösteren 0,0 ile 1,0 arasında bir sayı. AUC değeri 1, 0'a ne kadar yakın olursa modelin sınıfları birbirinden ayırma yeteneği o kadar iyi olur.
Örneğin, aşağıdaki resimde pozitif sınıfları (yeşil oval) negatif sınıflardan (mor dikdörtgen) mükemmel şekilde ayıran bir sınıflandırma modeli gösterilmektedir. Bu gerçekçi olmayan mükemmel modelin AUC değeri 1,0'dır:

Buna karşılık, aşağıdaki resimde rastgele sonuçlar üreten bir sınıflandırma modelinin sonuçları gösterilmektedir. Bu modelin AUC değeri 0,5'tir:

Evet, önceki modelin AUC değeri 0,0 değil 0,5.
Çoğu model, iki uç nokta arasında bir yerdedir. Örneğin, aşağıdaki model pozitifleri negatiflerden biraz ayırır ve bu nedenle 0,5 ile 1,0 arasında bir AUC'ye sahiptir:

AUC, sınıflandırma eşiği için ayarladığınız tüm değerleri yoksayar. Bunun yerine, AUC tüm olası sınıflandırma eşiklerini dikkate alır.
AUC ve ROC eğrileri arasındaki ilişki hakkında bilgi edinmek için simgeyi tıklayın.
AUC, ROC eğrisinin altındaki alanı temsil eder. Örneğin, pozitifleri negatiflerden mükemmel şekilde ayıran bir modelin ROC eğrisi aşağıdaki gibi görünür:

AUC, önceki resimde gri bölgenin alanıdır. Bu alışılmadık durumda alan, gri bölgenin uzunluğu (1,0) ile gri bölgenin genişliğinin (1,0) çarpımıdır. Bu nedenle, 1,0 ile 1,0'ın çarpımı tam olarak 1,0 AUC değerini verir. Bu, mümkün olan en yüksek AUC puanıdır.
Buna karşılık, sınıfları hiç ayıramayan bir sınıflandırma modelinin ROC eğrisi aşağıdaki gibidir. Bu gri bölgenin alanı 0,5'tir.

Daha tipik bir ROC eğrisi yaklaşık olarak aşağıdaki gibi görünür:

Bu eğrinin altındaki alanı manuel olarak hesaplamak çok zahmetli bir iş olur. Bu nedenle, çoğu AUC değeri genellikle bir program tarafından hesaplanır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: ROC ve AUC başlıklı makaleyi inceleyin.
k'da ortalama hassasiyet
Bir modelin, sıralanmış sonuçlar oluşturan tek bir istemdeki performansını özetleyen bir metrik (ör. kitap önerilerinin numaralandırılmış listesi). k'daki ortalama hassasiyet, her bir alakalı sonuç için k'daki hassasiyet değerlerinin ortalamasıdır. Bu nedenle, k'daki ortalama hassasiyet formülü şöyledir:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
Bu örnekte:
- \(n\) , listedeki alakalı öğelerin sayısıdır.
k tuşunda geri çağırma ile karşılaştırın.
B
referans değer
Başka bir modelin (genellikle daha karmaşık bir model) ne kadar iyi performans gösterdiğini karşılaştırmak için referans noktası olarak kullanılan model. Örneğin, bir lojistik regresyon modeli, derin model için iyi bir referans değer olabilir.
Temel, belirli bir sorun için model geliştiricilerin yeni modelin faydalı olması amacıyla yeni modelin ulaşması gereken minimum beklenen performansı ölçmesine yardımcı olur.
Boole Soruları (BoolQ)
Bir LLM'nin evet/hayır sorularını yanıtlama yeterliliğini değerlendirmek için kullanılan veri kümesi. Veri kümesindeki her bir zorluğun üç bileşeni vardır:
- Sorgu
- Sorgunun yanıtını ima eden bir pasaj.
- Evet veya hayır olan doğru yanıt.
Örneğin:
- Sorgu: Michigan'da nükleer santral var mı?
- Passage: ...üç nükleer santral, Michigan'ın elektrik ihtiyacının yaklaşık% 30'unu karşılıyor.
- Doğru yanıt: Evet
Araştırmacılar, soruları anonimleştirilmiş ve toplanmış Google Arama sorgularından topladıktan sonra bilgileri temellendirmek için Wikipedia sayfalarını kullandı.
Daha fazla bilgi için BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions (BoolQ: Doğal Evet/Hayır Sorularının Şaşırtıcı Zorluğunu Keşfetme) başlıklı makaleyi inceleyin.
BoolQ, SuperGLUE topluluğunun bir bileşenidir.
BoolQ
Boole Soruları'nın kısaltmasıdır.
C
CB
CommitmentBank'ın kısaltması.
Karakter N-gram F-puanı (ChrF)
Makine çevirisi modellerini değerlendirmek için kullanılan bir metrik. Karakter N-gram F puanı, referans metindeki N-gramların, bir makine öğrenimi modelinin oluşturulan metnindeki N-gramlarla ne ölçüde örtüştüğünü belirler.
Karakter N-gram F-puanı, ROUGE ve BLEU ailelerindeki metriklere benzer. Ancak:
- Karakter N-gram F puanı, karakter N-gram'ları üzerinde çalışır.
- ROUGE ve BLEU, kelime N-gramları veya jetonlar üzerinde çalışır.
Olası Alternatif Seçimi (COPA)
Bir LLM'nin bir önermeye verilen iki alternatif yanıttan hangisinin daha iyi olduğunu ne kadar iyi belirleyebildiğini değerlendirmek için kullanılan veri kümesi. Veri kümesindeki her görev üç bileşenden oluşur:
- Genellikle bir ifadenin ardından gelen bir soru
- Önermede sorulan soruya verilebilecek iki olası yanıt (biri doğru, diğeri yanlış)
- Doğru yanıt
Örneğin:
- Önerme: Adamın ayak parmağı kırıldı. Bunun NEDENİ neydi?
- Olası yanıtlar:
- He got a hole in his sock.
- Ayağına çekiç düşürdü.
- Doğru cevap: 2
COPA, SuperGLUE topluluğunun bir bileşenidir.
CommitmentBank (CB)
Bir LLM'nin, bir pasajın yazarının bu pasajdaki hedef bir maddeye inanıp inanmadığını belirleme konusundaki yeterliliğini değerlendirmeye yönelik bir veri kümesi. Veri kümesindeki her giriş şunları içerir:
- Bir pasaj
- Bu pasajdaki bir hedef cümle
- Parçanın yazarının hedef maddeye inanıp inanmadığını belirten bir Boole değeri.
Örneğin:
- Parça: Artemis'in kahkahasını duymak ne kadar eğlenceliydi. Ne kadar ciddi bir çocuk. Mizah anlayışı olduğunu bilmiyordum.
- Hedef madde: Mizah anlayışı var
- Boole: Doğru (True), yani yazar hedef maddenin doğru olduğuna inanıyor.
CommitmentBank, SuperGLUE topluluğunun bir bileşenidir.
COPA
Olası Alternatif Seçimi'nin kısaltması.
maliyet
Kaybın eş anlamlısı.
karşıolgusal adalet
Bir adalet metriği, bir sınıflandırma modelinin bir birey için aynı sonucu üretip üretmediğini kontrol eder. Bu birey, bir veya daha fazla hassas özellik dışında ilk bireyle aynıdır. Karşı olgusal adalet için bir sınıflandırma modelini değerlendirmek, modeldeki olası önyargı kaynaklarını ortaya çıkarmanın bir yöntemidir.
Daha fazla bilgi için aşağıdaki kaynaklardan birine bakın:
- Makine Öğrenimi Hızlandırılmış Kursu'nda Adalet: Karşıolgusal adalet.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
çapraz entropi
Log Loss'un çok sınıflı sınıflandırma sorunlarına genelleştirilmiş halidir. Çapraz entropi, iki olasılık dağılımı arasındaki farkı ölçer. Ayrıca şaşırtıcılık konusuna da bakın.
kümülatif dağılım fonksiyonu (KDF)
Hedef değerden küçük veya bu değere eşit örneklerin sıklığını tanımlayan bir işlev. Örneğin, sürekli değerlerin normal dağılımını ele alalım. Bir kümülatif dağılım fonksiyonu, örneklerin yaklaşık% 50'sinin ortalamadan küçük veya ortalamaya eşit olması gerektiğini ve örneklerin yaklaşık% 84'ünün ortalamanın bir standart sapma üzerinde olmaması gerektiğini gösterir.
D
demografik eşitlik
Bir modelin sınıflandırma sonuçları belirli bir hassas özelliğe bağlı değilse karşılanan bir adalet metriği.
Örneğin, hem Lilliputlular hem de Brobdingnaglılar Glubbdubdrib Üniversitesi'ne başvuruyorsa bir grubun ortalama olarak diğerinden daha nitelikli olup olmadığına bakılmaksızın, kabul edilen Lilliputluların yüzdesi ile kabul edilen Brobdingnaglıların yüzdesi aynı olduğunda demografik eşitlik sağlanır.
Eşitlenmiş olasılıklar ve fırsat eşitliği ile karşılaştırıldığında, bu kavramlar toplu sınıflandırma sonuçlarının hassas özelliklere bağlı olmasına izin verir ancak belirli gerçek etiketleri için sınıflandırma sonuçlarının hassas özelliklere bağlı olmasına izin vermez. Demografik eşitlik için optimizasyon yaparken yapılan fedakarlıkları inceleyen bir görselleştirme için "Daha akıllı makine öğrenimiyle ayrımcılığa karşı mücadele etme" başlıklı makaleye bakın.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Adalet: demografik eşitlik bölümüne bakın.
E
toprak taşıma aracı mesafesi (EMD)
İki dağıtımın göreli benzerliğinin ölçüsü. Toprak taşıma mesafesi ne kadar düşükse dağıtımlar o kadar benzerdir.
düzenleme mesafesi
İki metin dizesinin birbirine ne kadar benzediğinin ölçüsü. Makine öğreniminde düzenleme mesafesi şu nedenlerle faydalıdır:
- Düzenleme mesafesini hesaplamak kolaydır.
- Düzenleme mesafesi, birbirine benzer olduğu bilinen iki dizeyi karşılaştırabilir.
- Düzenleme mesafesi, farklı dizelerin belirli bir dizeye ne kadar benzediğini belirleyebilir.
Düzenleme mesafesinin, her biri farklı dize işlemleri kullanan çeşitli tanımları vardır. Örnek için Levenshtein mesafesi başlıklı makaleyi inceleyin.
ampirik kümülatif dağılım işlevi (eCDF veya EDF)
Gerçek bir veri kümesinden alınan kümülatif dağılım fonksiyonu deneysel ölçümlere dayanır. Fonksiyonun x ekseni boyunca herhangi bir noktadaki değeri, veri kümesindeki gözlemlerin belirtilen değerden küçük veya bu değere eşit olan kısmıdır.
entropi
Bilgi teorisinde, bir olasılık dağılımının ne kadar tahmin edilemez olduğunun açıklamasıdır. Alternatif olarak entropi, her bir örneğin ne kadar bilgi içerdiği şeklinde de tanımlanır. Bir dağılım, rastgele değişkenin tüm değerleri eşit olasılıklı olduğunda mümkün olan en yüksek entropiye sahiptir.
"0" ve "1" olmak üzere iki olası değere sahip bir kümenin entropisi (örneğin, ikili sınıflandırma problemindeki etiketler) aşağıdaki formüle sahiptir:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
Bu örnekte:
- H, entropidir.
- p, "1" örneklerinin kesridir.
- q, "0" örneklerinin kesridir. q = (1 - p) olduğunu unutmayın.
- log genellikle log2'dir. Bu durumda, entropi birimi bit'tir.
Örneğin, aşağıdakileri varsayalım:
- 100 örnekte "1" değeri var
- 300 örnekte "0" değeri var
Bu nedenle, entropi değeri şöyledir:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = örnek başına 0,81 bit
Mükemmel dengelenmiş bir küme (örneğin, 200 "0" ve 200 "1") örneği başına 1,0 bit entropiye sahip olur. Bir küme dengesizleştiğinde entropisi 0, 0'a doğru hareket eder.
Karar ağaçlarında entropi, bölücünün sınıflandırma karar ağacının büyümesi sırasında koşulları seçmesine yardımcı olmak için bilgi kazancını formüle etmeye yardımcı olur.
Entropiyi şunlarla karşılaştırın:
- gini impurity
- Çapraz entropi kayıp fonksiyonu
Entropiye genellikle Shannon entropisi denir.
Daha fazla bilgi için Karar Ormanları kursundaki Sayısal özelliklerle ikili sınıflandırma için tam ayırıcı başlıklı makaleyi inceleyin.
fırsat eşitliği
Bir modelin, hassas özelliğin tüm değerleri için istenen sonucu eşit derecede iyi tahmin edip etmediğini değerlendirmek üzere kullanılan bir adalet metriği. Diğer bir deyişle, bir model için istenen sonuç pozitif sınıf ise amaç, gerçek pozitif oranının tüm gruplar için aynı olmasıdır.
Fırsat eşitliği, eşitlenmiş olasılıklar ile ilgilidir. Bu da tüm gruplar için hem doğru pozitif oranlarının hem de yanlış pozitif oranlarının aynı olmasını gerektirir.
Glubbdubdrib Üniversitesi'nin hem Lilliputluları hem de Brobdingnaglıları zorlu bir matematik programına kabul ettiğini varsayalım. Lilliputluların ortaokullarında matematik derslerinden oluşan kapsamlı bir müfredat uygulanır ve öğrencilerin büyük çoğunluğu üniversite programına katılmaya hak kazanır. Brobdingnaglıların ortaokullarında matematik dersi verilmez ve sonuç olarak, öğrencilerin çok daha azı yeterli bilgiye sahiptir. Nitelikli öğrenciler, Lilliputlu veya Brobdingnaglı olmalarına bakılmaksızın eşit olasılıkla kabul ediliyorsa milliyet (Lilliputlu veya Brobdingnaglı) açısından "kabul edildi" tercih edilen etiketi için fırsat eşitliği sağlanmış olur.
Örneğin, Glubbdubdrib Üniversitesi'ne 100 Lilliputlu ve 100 Brobdingnaglı başvurduğunu ve kabul kararlarının aşağıdaki gibi verildiğini varsayalım:
Tablo 1. Lilliputian başvuru sahipleri (%90'ı nitelikli)
| Uygun | Uygun Değil | |
|---|---|---|
| Kabul edildi | 45 | 3 |
| Reddedildi | 45 | 7 |
| Toplam | 90 | 10 |
|
Kabul edilen nitelikli öğrenci yüzdesi: 45/90 =%50 Reddedilen niteliksiz öğrenci yüzdesi: 7/10 =%70 Kabul edilen toplam Lilliputlu öğrenci yüzdesi: (45+3)/100 = %48 |
||
Tablo 2. Brobdingnagian başvuru sahipleri (%10'u nitelikli):
| Uygun | Uygun Değil | |
|---|---|---|
| Kabul edildi | 5 | 9 |
| Reddedildi | 5 | 81 |
| Toplam | 10 | 90 |
|
Kabul edilen uygun öğrenci yüzdesi: 5/10 =%50 Reddedilen uygun olmayan öğrenci yüzdesi: 81/90 =%90 Kabul edilen toplam Brobdingnagian öğrenci yüzdesi: (5+9)/100 = %14 |
||
Yukarıdaki örnekler, nitelikli Lilliputluların ve Brobdingnaglıların kabul edilme şansı% 50 olduğundan nitelikli öğrencilerin kabulü için fırsat eşitliğini sağlar.
Fırsat eşitliği karşılanırken aşağıdaki iki adalet metriği karşılanmaz:
- Demografik eşitlik: Lilliputlular ve Brobdingnaglılar üniversiteye farklı oranlarda kabul ediliyor. Lilliputlu öğrencilerin% 48'i kabul edilirken Brobdingnaglı öğrencilerin yalnızca% 14'ü kabul ediliyor.
- Eşitlenmiş olasılıklar: Nitelikli Lilliput ve Brobdingnag öğrencileri kabul edilme konusunda eşit şansa sahip olsa da niteliksiz Lilliput ve Brobdingnag öğrencileri reddedilme konusunda eşit şansa sahip olma koşulu karşılanmaz. Uygun olmayan Lilliputluların reddedilme oranı% 70, uygun olmayan Brobdingnaglıların reddedilme oranı ise% 90'dır.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Adalet: Fırsat eşitliği bölümüne bakın.
eşitlenmiş oranlar
Bir modelin, pozitif sınıf ve negatif sınıf ile ilgili olarak bir hassas özelliğin tüm değerleri için sonuçları eşit derecede iyi tahmin edip etmediğini değerlendirmek için kullanılan bir adalet metriği. Bu metrik, yalnızca bir sınıfı veya diğer sınıfı değerlendirmez. Başka bir deyişle, tüm gruplar için hem gerçek pozitif oranı hem de yanlış negatif oranı aynı olmalıdır.
Eşitlenmiş olasılık, yalnızca tek bir sınıfın (pozitif veya negatif) hata oranlarına odaklanan fırsat eşitliği ile ilgilidir.
Örneğin, Glubbdubdrib Üniversitesi'nin hem Lilliputluları hem de Brobdingnaglıları zorlu bir matematik programına kabul ettiğini varsayalım. Lilliputluların ortaokullarında matematik derslerinden oluşan sağlam bir müfredat uygulanır ve öğrencilerin büyük çoğunluğu üniversite programına katılmaya hak kazanır. Brobdingnaglıların ortaokullarında matematik dersleri verilmez ve sonuç olarak, öğrencilerinin çok daha azı yeterli niteliklere sahiptir. Başvuru sahibinin Lilliputian veya Brobdingnagian olması fark etmeksizin, nitelikli olması durumunda programa kabul edilme olasılığı eşit, nitelikli olmaması durumunda ise reddedilme olasılığı eşit olduğu sürece eşit olasılık koşulu karşılanmış olur.
Glubbdubdrib Üniversitesi'ne 100 Lilliputlu ve 100 Brobdingnaglı başvurduğunu ve kabul kararlarının aşağıdaki şekilde verildiğini varsayalım:
Tablo 3. Lilliputian başvuru sahipleri (%90'ı nitelikli)
| Uygun | Uygun Değil | |
|---|---|---|
| Kabul edildi | 45 | 2 |
| Reddedildi | 45 | 8 |
| Toplam | 90 | 10 |
|
Kabul edilen uygun öğrenci yüzdesi: 45/90 =%50 Reddedilen uygun olmayan öğrenci yüzdesi: 8/10 =%80 Toplamda kabul edilen Lilliputlu öğrenci yüzdesi: (45+2)/100 = %47 |
||
Tablo 4. Brobdingnagian başvuru sahipleri (%10'u nitelikli):
| Uygun | Uygun Değil | |
|---|---|---|
| Kabul edildi | 5 | 18 |
| Reddedildi | 5 | 72 |
| Toplam | 10 | 90 |
|
Kabul edilen nitelikli öğrenci yüzdesi: 5/10 =%50 Reddedilen niteliksiz öğrenci yüzdesi: 72/90 =%80 Kabul edilen Brobdingnagian öğrencilerin toplam yüzdesi: (5+18)/100 = %23 |
||
Nitelikli Lilliput ve Brobdingnag öğrencilerin kabul edilme olasılığı% 50, niteliksiz Lilliput ve Brobdingnag öğrencilerin reddedilme olasılığı ise% 80 olduğundan eşit olasılık koşulu karşılanmaktadır.
Eşitlenmiş olasılık, "Equality of Opportunity in Supervised Learning" adlı makalede şu şekilde tanımlanır: "Ŷ tahmin edicisi, Y koşullu olarak Ŷ ve A bağımsızsa korumalı A özelliği ve Y sonucu açısından eşitlenmiş olasılığı karşılar."
evals
Öncelikli olarak LLM değerlendirmeleri için kısaltma olarak kullanılır. Daha geniş bir ifadeyle evals, herhangi bir değerlendirme biçiminin kısaltmasıdır.
değerlendirme
Bir modelin kalitesini ölçme veya farklı modelleri birbiriyle karşılaştırma süreci.
Gözetimli makine öğrenimi modelini değerlendirmek için genellikle doğrulama kümesi ve test kümesi ile karşılaştırırsınız. LLM'leri değerlendirme genellikle daha kapsamlı kalite ve güvenlik değerlendirmelerini içerir.
tam eşleme
Modelin çıkışının değerlendirme veri kümesindeki gerçek doğru veya referans metinle tam olarak eşleştiği ya da eşleşmediği bir metrik. Örneğin, gerçek doğru turuncu ise tam eşlemeyi karşılayan tek model çıkışı turuncu olur.
Tam eşleşme, çıkışı bir dizi (öğelerin sıralanmış listesi) olan modelleri de değerlendirebilir. Genel olarak, tam eşleme için oluşturulan sıralı listenin, değerlendirme veri kümesiyle tam olarak eşleşmesi gerekir. Yani her iki listedeki her öğe aynı sırada olmalıdır. Bununla birlikte, kesin referans birden fazla doğru diziden oluşuyorsa tam eşleşme için modelin çıkışının doğru dizilerden biriyle eşleşmesi yeterlidir.
Aşırı Özetleme (xsum)
Bir LLM'nin tek bir belgeyi özetleme yeteneğini değerlendirmek için kullanılan veri kümesi. Veri kümesindeki her giriş şunlardan oluşur:
- British Broadcasting Corporation (BBC) tarafından yazılmış bir belge.
- İlgili dokümanın tek cümlelik özeti.
Ayrıntılı bilgi için Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
C
F1
Hem hassasiyete hem de geri çağırmaya dayanan bir "toplama" ikili sınıflandırma metriği. Formül şu şekildedir:
adalet metriği
Ölçülebilir bir "adalet" tanımı. Sık kullanılan bazı adalet metrikleri şunlardır:
- eşitlenmiş olasılıklar (equalized odds)
- tahmini eşitlik
- karşı olgusal adalet (counterfactual fairness)
- demografik eşitlik
Birçok adalet metriği birbirini dışlar. Adalet metriklerinin uyumsuzluğu başlıklı makaleyi inceleyin.
yanlış negatif (FN)
Modelin negatif sınıfı yanlışlıkla tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olmadığını (negatif sınıf) tahmin ediyor ancak bu e-posta iletisi aslında spam.
yanlış negatif oranı
Modelin yanlışlıkla negatif sınıfı tahmin ettiği gerçek pozitif örneklerin oranı. Aşağıdaki formül, yanlış negatif oranını hesaplar:
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Eşikler ve karmaşıklık matrisi bölümüne bakın.
yanlış pozitif (FP)
Modelin pozitif sınıfı yanlışlıkla tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam (pozitif sınıf) olduğunu tahmin eder ancak bu e-posta iletisi aslında spam değildir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Eşikler ve karmaşıklık matrisi bölümüne bakın.
yanlış pozitif oranı (FPR)
Modelin pozitif sınıfı yanlışlıkla tahmin ettiği gerçek negatif örneklerin oranı. Aşağıdaki formül, yanlış pozitif oranını hesaplar:
Yanlış pozitif oranı, ROC eğrisindeki x eksenidir.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Sınıflandırma: ROC ve AUC başlıklı makaleyi inceleyin.
özellik önem düzeyleri
Değişken önemleri ile eş anlamlıdır.
temel model
Çok büyük ve çeşitli bir eğitim kümesi üzerinde eğitilmiş çok büyük bir önceden eğitilmiş model. Temel model, aşağıdakilerin ikisini de yapabilir:
- Çok çeşitli isteklere iyi yanıt verin.
- Ek ince ayar veya diğer özelleştirmeler için temel model olarak kullanılabilir.
Başka bir deyişle, temel model genel anlamda zaten çok yeteneklidir ancak belirli bir görev için daha da faydalı olacak şekilde özelleştirilebilir.
başarı oranı
Bir makine öğrenimi modelinin oluşturduğu metni değerlendirmek için kullanılan bir metrik. Başarı oranı, oluşturulan "başarılı" metin çıkışlarının sayısının, oluşturulan toplam metin çıkışı sayısına bölünmesiyle elde edilir. Örneğin, bir büyük dil modeli 10 kod bloğu oluşturduysa ve bunların beşi başarılı olduysa başarı oranı %50 olur.
Başarı oranı, istatistiklerde genel olarak faydalı olsa da makine öğreniminde bu metrik, öncelikli olarak kod oluşturma veya matematik problemleri gibi doğrulanabilir görevleri ölçmek için kullanılır.
G
Gini kirliliği
Entropiye benzer bir metrik. Ayırıcılar, sınıflandırma karar ağaçları için koşullar oluşturmak üzere gini kirliliğinden veya entropiden elde edilen değerleri kullanır. Bilgi kazancı, entropiden elde edilir. Gini kirliliğinden elde edilen metrik için evrensel olarak kabul edilen eşdeğer bir terim yoktur. Ancak bu adsız metrik, bilgi kazancı kadar önemlidir.
Gini kirliliğine Gini endeksi veya kısaca Gini de denir.
H
menteşe kaybı
Her bir eğitim örneğinden mümkün olduğunca uzak karar sınırını bulmak için tasarlanmış, sınıflandırma için bir kayıp işlevleri ailesi. Bu sayede, örnekler ile sınır arasındaki marj en üst düzeye çıkarılır. KSVM'ler, menteşe kaybını (veya kare menteşe kaybı gibi ilgili bir işlevi) kullanır. İkili sınıflandırma için menteşe kaybı işlevi aşağıdaki şekilde tanımlanır:
Burada y, -1 veya +1 olan gerçek etikettir ve y', sınıflandırma modelinin ham çıkışıdır:
Sonuç olarak, menteşe kaybı ile (y * y') arasındaki ilişki aşağıdaki gibi görünür:

I
Adalet metriklerinin uyumsuzluğu
Bazı adalet kavramlarının birbiriyle uyumlu olmadığı ve aynı anda karşılanamayacağı fikri. Sonuç olarak, adalet kavramını ölçmek için tüm makine öğrenimi sorunlarına uygulanabilecek tek bir evrensel metrik yoktur.
Bu durum cesaret kırıcı olsa da adalet metriklerinin uyumsuzluğu, adaletle ilgili çabaların boşuna olduğu anlamına gelmez. Bunun yerine, adalet kavramının belirli bir makine öğrenimi problemi için bağlamsal olarak tanımlanması gerektiğini ve kullanım alanlarına özgü zararların önlenmesinin amaçlandığını belirtir.
Adalet metriklerinin uyumsuzluğu hakkında daha ayrıntılı bir tartışma için "On the (im)possibility of fairness" başlıklı makaleyi inceleyin.
bireysel adalet
Benzer kişilerin benzer şekilde sınıflandırılıp sınıflandırılmadığını kontrol eden bir adalet metriği. Örneğin, Brobdingnagian Akademisi, aynı notlara ve standart test puanlarına sahip iki öğrencinin kabul edilme olasılığının eşit olmasını sağlayarak bireysel adalet ilkesini karşılamak isteyebilir.
Bireysel adalet kavramının tamamen "benzerliği" nasıl tanımladığınıza (bu durumda notlar ve test puanları) bağlı olduğunu ve benzerlik metriğiniz önemli bilgileri (ör. öğrencinin müfredatının zorluğu) kaçırırsa yeni adalet sorunları ortaya çıkarma riskiyle karşılaşabileceğinizi unutmayın.
Bireysel adalet hakkında daha ayrıntılı bilgi için "Farkındalıkla Adalet" başlıklı makaleyi inceleyin.
bilgi kazancı
Karar ağaçlarında, bir düğümün entropisi ile alt düğümlerinin entropisinin örnek sayısına göre ağırlıklı toplamı arasındaki fark. Bir düğümün entropisi, o düğümdeki örneklerin entropisidir.
Örneğin, aşağıdaki entropi değerlerini ele alalım:
- üst düğümün entropisi = 0,6
- 16 alakalı örneğe sahip bir alt düğümün entropisi = 0,2
- 24 alakalı örneği olan başka bir alt düğümün entropisi = 0,1
Bu nedenle, örneklerin% 40'ı bir alt düğümde, %60'ı ise diğer alt düğümdedir. Bu nedenle:
- alt düğümlerin ağırlıklı entropi toplamı = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Bu nedenle, bilgi kazancı şöyledir:
- bilgi kazancı = üst düğümün entropisi - alt düğümlerin ağırlıklı entropi toplamı
- bilgi kazancı = 0,6 - 0,14 = 0,46
Çoğu bölücü, bilgi kazanımını en üst düzeye çıkaran koşullar oluşturmayı amaçlar.
değerlendiriciler arası uyum
İnsan derecelendirme uzmanlarının bir görevi yaparken ne sıklıkta aynı fikirde olduğunun ölçüsü. Değerlendirme uzmanları aynı fikirde değilse görev talimatlarının iyileştirilmesi gerekebilir. Bazen yorumlayıcılar arası anlaşma veya değerlendirenler arası güvenilirlik olarak da adlandırılır. Ayrıca, en popüler gözlemciler arası anlaşma ölçümlerinden biri olan Cohen's kappa'ya bakın.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Kategorik veriler: Sık karşılaşılan sorunlar bölümüne bakın.
L
L1 kaybı
Gerçek etiket değerleri ile modelin tahmin ettiği değerler arasındaki farkın mutlak değerini hesaplayan bir kayıp işlevi. Örneğin, beş örnekten oluşan bir toplu işlem için L1 kaybının hesaplanması aşağıda verilmiştir:
| Örneğin gerçek değeri | Modelin tahmini değeri | Delta'nın mutlak değeri |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 kaybı | ||
L1 kaybı, L2 kaybına kıyasla aykırı değerlere karşı daha az hassastır.
Ortalama mutlak hata, örnek başına ortalama L1 kaybıdır.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Doğrusal Regresyon: Kayıp bölümüne bakın.
L2 kaybı
Gerçek etiket değerleri ile modelin tahmin ettiği değerler arasındaki farkın karesini hesaplayan bir kayıp işlevi. Örneğin, beş örnekten oluşan bir toplu işlem için L2 kaybının hesaplanması aşağıda verilmiştir:
| Örneğin gerçek değeri | Modelin tahmini değeri | Delta kare |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 kaybı | ||
Kare alma işlemi nedeniyle L2 kaybı, aykırı değerlerin etkisini artırır. Yani L2 kaybı, kötü tahminlere L1 kaybından daha güçlü tepki verir. Örneğin, önceki toplu iş için L1 kaybı 16 yerine 8 olur. 16 aykırı değerden 9'unun tek bir aykırı değerden kaynaklandığına dikkat edin.
Regresyon modelleri genellikle kayıp işlevi olarak L2 kaybını kullanır.
Ortalama Karesel Hata, örnek başına ortalama L2 kaybıdır. Kare kaybı, L2 kaybının diğer adıdır.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Lojistik regresyon: Kayıp ve düzenlileştirme bölümüne bakın.
LLM değerlendirmeleri (evals)
Büyük dil modellerinin (LLM'ler) performansını değerlendirmek için kullanılan bir dizi metrik ve karşılaştırma. Özetle, LLM değerlendirmeleri:
- Araştırmacıların, LLM'lerin iyileştirilmesi gereken alanları belirlemesine yardımcı olun.
- Farklı büyük dil modellerini karşılaştırmak ve belirli bir görev için en iyi büyük dil modelini belirlemek amacıyla kullanılır.
- Büyük dil modellerinin güvenli ve etik bir şekilde kullanılmasını sağlamaya yardımcı olur.
Daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'ndaki Büyük dil modelleri (LLM'ler) bölümüne bakın.
mağlubiyetin ardından
Gözetimli bir modelin eğitimi sırasında, modelin tahmininin etiketinden ne kadar uzak olduğunu gösteren bir ölçü.
Kayıp işlevi, kaybı hesaplar.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Doğrusal regresyon: Kayıp bölümüne bakın.
kayıp fonksiyonu
Eğitim veya test sırasında, bir örnek grubu üzerindeki kaybı hesaplayan matematiksel bir işlev. Bir kayıp işlevi, iyi tahminler yapan modeller için kötü tahminler yapan modellere göre daha düşük bir kayıp değeri döndürür.
Eğitimin amacı genellikle bir kayıp fonksiyonunun döndürdüğü kaybı en aza indirmektir.
Birçok farklı türde kayıp fonksiyonu vardır. Oluşturduğunuz model türü için uygun kayıp işlevini seçin. Örneğin:
- L2 kaybı (veya karesi alınmış ortalama hata), doğrusal regresyon için kayıp işlevidir.
- Log Loss, lojistik regresyonun kayıp işlevidir.
A
matrisi çarpanlara ayırma
Matematikte, skaler çarpımı hedef matrise yaklaşan matrisleri bulma mekanizması.
Öneri sistemlerinde hedef matris, genellikle kullanıcıların öğelerle ilgili puanlarını içerir. Örneğin, bir film öneri sisteminin hedef matrisi aşağıdaki gibi görünebilir. Burada pozitif tam sayılar kullanıcı derecelendirmelerini, 0 ise kullanıcının filmi derecelendirmediğini gösterir:
| Kazablanka | The Philadelphia Story | Black Panther | Wonder Woman | Ucuz Roman | |
|---|---|---|---|---|---|
| 1. Kullanıcı | 5,0 | 3,0 | 0,0 | 2,0 | 0,0 |
| 2. Kullanıcı | 4.0 | 0,0 | 0,0 | 1,0 | 5,0 |
| 3. Kullanıcı | 3,0 | 1,0 | 4.0 | 5,0 | 0,0 |
Film öneri sistemi, derecelendirilmemiş filmler için kullanıcı derecelendirmelerini tahmin etmeyi amaçlar. Örneğin, 1. Kullanıcı Black Panther'i beğenir mi?
Öneri sistemlerinde kullanılan bir yaklaşım, aşağıdaki iki matrisi oluşturmak için matris çarpanlarına ayırma yöntemini kullanmaktır:
- Kullanıcı sayısı X yerleştirme boyutu sayısı şeklinde oluşturulan bir kullanıcı matrisi.
- Öğe matrisi, yerleştirme boyutlarının sayısı X öğe sayısı şeklinde oluşturulur.
Örneğin, üç kullanıcımız ve beş öğemiz üzerinde matrisi çarpanlara ayırma yöntemini kullandığımızda aşağıdaki kullanıcı matrisi ve öğe matrisi elde edilebilir:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Kullanıcı matrisi ile öğe matrisinin nokta çarpımı, yalnızca orijinal kullanıcı puanlarını değil, aynı zamanda her kullanıcının izlemediği filmlerle ilgili tahminleri de içeren bir öneri matrisi oluşturur. Örneğin, Kullanıcı 1'in Casablanca filmine verdiği 5, 0 puanı ele alalım. Öneri matrisinde bu hücreye karşılık gelen skaler çarpım, umarız 5,0 civarındadır ve şöyledir:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Daha da önemlisi, 1. Kullanıcı Black Panther'ı beğenir mi? İlk satır ve üçüncü sütuna karşılık gelen nokta çarpımı, 4,3 olarak tahmin edilen bir puanı verir:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Matrisi çarpanlara ayırma genellikle hedef matristen çok daha kompakt olan bir kullanıcı matrisi ve öğe matrisi oluşturur.
MBPP
Mostly Basic Python Problems kısaltması.
Ortalama mutlak hata (MAE)
L1 kaybı kullanıldığında örnek başına ortalama kayıp. Ortalama mutlak hatayı aşağıdaki şekilde hesaplayın:
- Bir toplu iş için L1 kaybını hesaplayın.
- L1 kaybını gruptaki örnek sayısına bölün.
Örneğin, aşağıdaki beş örnekten oluşan toplu işlemde L1 kaybının hesaplanmasını ele alalım:
| Örneğin gerçek değeri | Modelin tahmini değeri | Kayıp (gerçek ve tahmin edilen değer arasındaki fark) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L1 kaybı | ||
Bu nedenle, L1 kaybı 8 ve örnek sayısı 5'tir. Bu nedenle, ortalama mutlak hata şöyledir:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Ortalama mutlak hatayı ortalama karesel hata ve kök ortalama karesel hata ile karşılaştırın.
k'da ortalama hassasiyet (mAP@k)
Bir doğrulama veri kümesindeki tüm k değerinde ortalama hassasiyet puanlarının istatistiksel ortalaması. k'da ortalama hassasiyetin bir kullanım alanı, öneri sistemi tarafından oluşturulan önerilerin kalitesini değerlendirmektir.
"Ortalama" ifadesi gereksiz gibi görünse de metriğin adı uygundur. Bu metrik, birden fazla k değerinde ortalama kesinlik değerinin ortalamasını bulur.
Ortalama Karesel Hata (MSE)
L2 kaybı kullanıldığında örnek başına ortalama kayıp. Ortalama karesel hatayı aşağıdaki şekilde hesaplayın:
- Bir toplu iş için L2 kaybını hesaplayın.
- L2 kaybını toplu işteki örnek sayısına bölün.
Örneğin, aşağıdaki beş örneklik gruptaki kaybı göz önünde bulundurun:
| Gerçek değer | Modelin tahmini | Kayıp | Karesel kayıp |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 kaybı | |||
Bu nedenle, ortalama karesel hata şöyledir:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Ortalama karesel hata, özellikle doğrusal regresyon için popüler bir eğitim optimizasyon aracıdır.
Karesel ortalama hatayı ortalama mutlak hata ve kök ortalama kare hatası ile karşılaştırın.
TensorFlow Playground, kayıp değerlerini hesaplamak için ortalama kare hatayı kullanır.
metrik
Önemsediğiniz bir istatistik.
Hedef, makine öğrenimi sisteminin optimize etmeye çalıştığı bir metriktir.
Metrics API (tf.metrics)
Modelleri değerlendirmek için kullanılan bir TensorFlow API'si. Örneğin, tf.metrics.accuracy, bir modelin tahminlerinin etiketlerle ne sıklıkta eşleştiğini belirler.
minimax kaybı
Üretilen verilerin dağıtımı ile gerçek veriler arasındaki çapraz entropiye dayalı olarak üretken çekişmeli ağlar için bir kayıp işlevi.
Minimax kaybı, üretken rakip ağları açıklamak için ilk makalede kullanılmıştır.
Daha fazla bilgi için Üretken Çekişmeli Ağlar kursundaki Kayıp İşlevleri bölümüne bakın.
model kapasitesi
Bir modelin öğrenebileceği sorunların karmaşıklığı. Bir modelin öğrenebileceği sorunlar ne kadar karmaşıksa modelin kapasitesi de o kadar yüksek olur. Bir modelin kapasitesi genellikle model parametrelerinin sayısıyla artar. Sınıflandırma modeli kapasitesinin resmi tanımı için VC boyutu başlıklı makaleyi inceleyin.
İlgiyi Artırma
Öğrenme adımının yalnızca mevcut adımdaki türeve değil, aynı zamanda hemen önceki adımın türevlerine de bağlı olduğu gelişmiş bir gradyan iniş algoritması. Momentum, zaman içindeki gradyanların üstel olarak ağırlıklandırılmış hareketli ortalamasını hesaplamayı içerir. Bu, fizikteki momentuma benzer. Momentum, öğrenmenin bazen yerel minimumlarda takılmasını önler.
Çoğunlukla Temel Python Sorunları (MBPP)
Bir LLM'nin Python kodu oluşturmadaki yeterliliğini değerlendirmek için kullanılan veri kümesi. Mostly Basic Python Problems (Çoğunlukla Temel Python Sorunları), yaklaşık 1.000 adet kitle kaynaklı programlama sorunu sunar. Veri kümesindeki her sorun şunları içerir:
- Görev açıklaması
- Çözüm kodu
- Üç otomatik test durumu
H
negatif sınıf
İkili sınıflandırmada bir sınıfa pozitif, diğerine ise negatif adı verilir. Pozitif sınıf, modelin test ettiği şey veya etkinliktir. Negatif sınıf ise diğer olasılıktır. Örneğin:
- Tıbbi bir testteki negatif sınıf "tümör yok" olabilir.
- Bir e-posta sınıflandırma modelindeki negatif sınıf "spam değil" olabilir.
Pozitif sınıfla karşılaştırın.
O
hedef
Algoritmanızın optimize etmeye çalıştığı bir metrik.
amaç işlevi
Bir modelin optimize etmeyi amaçladığı matematiksel formül veya metrik. Örneğin, doğrusal regresyonun amaç işlevi genellikle Ortalama Karesel Kayıp'tır. Bu nedenle, doğrusal regresyon modeli eğitilirken eğitim, ortalama kare kaybını en aza indirmeyi amaçlar.
Bazı durumlarda amaç, hedef işlevi en üst düzeye çıkarmaktır. Örneğin, amaç işlevi doğruluksa hedef, doğruluğu en üst düzeye çıkarmaktır.
Ayrıca kayıp konusuna da bakın.
P
k'da pas (pass@k)
Büyük dil modelinin oluşturduğu kodun (ör. Python) kalitesini belirleyen bir metrik. Daha net bir ifadeyle, k değerinde geçme, oluşturulan k kod bloğundan en az birinin tüm birim testlerini geçme olasılığını gösterir.
Büyük dil modelleri, karmaşık programlama sorunları için genellikle iyi kod oluşturmakta zorlanır. Yazılım mühendisleri, büyük dil modelinden aynı sorun için birden fazla (k) çözüm üretmesini isteyerek bu soruna uyum sağlar. Ardından, yazılım mühendisleri çözümlerin her birini birim testlerine göre test eder. k'da geçme hesaplaması birim testlerinin sonucuna bağlıdır:
- Bu çözümlerden biri veya daha fazlası birim testini geçerse LLM, kod oluşturma görevini geçer.
- Çözümlerden hiçbiri birim testini geçemezse LLM, kod oluşturma görevinde başarısız olur.
k pası için formül aşağıdaki gibidir:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Genel olarak, k değerleri ne kadar yüksek olursa k'da geçme puanları da o kadar yüksek olur. Ancak k değerleri ne kadar yüksek olursa büyük dil modeli ve birim testi kaynakları da o kadar fazla gerekir.
performans
Aşırı yüklenmiş terim aşağıdaki anlamlara sahiptir:
- Yazılım mühendisliğindeki standart anlam. Örneğin: Bu yazılım ne kadar hızlı (veya verimli) çalışıyor?
- Makine öğrenimindeki anlamı. Burada performans, şu soruyu yanıtlar: Bu model ne kadar doğru? Yani modelin tahminleri ne kadar iyi?
permütasyon değişkeni önemleri
Bir modelin tahmin hatasındaki artışı, özelliğin değerleri permütasyon işlemine tabi tutulduktan sonra değerlendiren bir değişken önemi türü. Permütasyonlu değişken önemi, modelden bağımsız bir metriktir.
şaşkınlık
Bir modelin görevini ne kadar iyi yerine getirdiğinin bir ölçüsüdür. Örneğin, görevinizin bir kullanıcının telefon klavyesinde yazdığı kelimenin ilk birkaç harfini okumak ve olası tamamlama kelimelerinin bir listesini sunmak olduğunu varsayalım. Bu görev için şaşkınlık (P), listenizin kullanıcının yazmaya çalıştığı gerçek kelimeyi içermesi için sunmanız gereken tahminlerin sayısıdır.
Perplexity, çapraz entropi ile şu şekilde ilişkilidir:
pozitif sınıf
Test ettiğiniz sınıf.
Örneğin, bir kanser modelindeki pozitif sınıf "tümör" olabilir. Bir e-posta sınıflandırma modelindeki pozitif sınıf "spam" olabilir.
Negatif sınıfla karşılaştırın.
PR AUC (PR eğrisinin altındaki alan)
Farklı sınıflandırma eşiği değerleri için (geri çağırma, hassasiyet) noktaları çizilerek elde edilen, enterpolasyonlu hassasiyet/geri çağırma eğrisinin altındaki alan.
precision
Aşağıdaki soruyu yanıtlayan sınıflandırma modelleri için bir metrik:
Model pozitif sınıfı tahmin ettiğinde tahminlerin yüzde kaçı doğruydu?
Formül şu şekildedir:
Bu örnekte:
- Gerçek pozitif, modelin pozitif sınıfı doğru tahmin ettiği anlamına gelir.
- Yanlış pozitif, modelin pozitif sınıfı yanlışlıkla tahmin ettiği anlamına gelir.
Örneğin, bir modelin 200 pozitif tahminde bulunduğunu varsayalım. Bu 200 pozitif tahminden:
- 150'si gerçek pozitifti.
- 50'si yanlış pozitifti.
Bu durumda:
Doğruluk ve geri çağırma ile karşılaştırın.
Daha fazla bilgi için Makine Öğrenimine Giriş Kursu'ndaki Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler bölümüne bakın.
k değerinde hassasiyet (precision@k)
Sıralanmış (sıralı) öğe listesini değerlendirmek için kullanılan bir metrik. k'daki duyarlık, listedeki ilk k öğeden "alakalı" olanların oranını tanımlar. Yani:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k değeri, döndürülen listenin uzunluğundan küçük veya ona eşit olmalıdır. Döndürülen listenin uzunluğunun hesaplamaya dahil olmadığını unutmayın.
Alaka düzeyi genellikle özneldir. Hatta uzman insan değerlendiriciler bile hangi öğelerin alakalı olduğu konusunda çoğu zaman anlaşamaz.
Şununla karşılaştır:
hassasiyet-geri çağırma eğrisi
Farklı sınıflandırma eşiklerinde hassasiyet ile geri çağırma arasındaki dengeyi gösteren bir eğri.
tahmin önyargısı
Veri kümesindeki tahminlerin ortalaması ile etiketlerin ortalaması arasındaki farkı gösteren değer.
Makine öğrenimi modellerindeki yanlılık terimi veya etik ve adalet açısından yanlılık ile karıştırılmamalıdır.
tahmini eşitlik
Belirli bir sınıflandırma modeli için dikkate alınan alt gruplarda hassasiyet oranlarının eşdeğer olup olmadığını kontrol eden bir adalet metriği.
Örneğin, üniversite kabulünü tahmin eden bir model, Lilliputlular ve Brobdingnaglılar için kesinlik oranı aynıysa milliyet açısından tahmini eşitliği karşılar.
Tahmini fiyat eşitliği bazen tahmini oran eşitliği olarak da adlandırılır.
Tahmini eşitlik hakkında daha ayrıntılı bilgi için "Adalet Tanımları Açıklaması" (bölüm 3.2.1) başlıklı makaleyi inceleyin.
tahmini fiyat eşitliği
Tahmini eşlik için kullanılan başka bir ad.
olasılık yoğunluk fonksiyonu
Tam olarak belirli bir değere sahip veri örneklerinin sıklığını belirleyen bir işlev. Bir veri kümesinin değerleri sürekli kayan noktalı sayılar olduğunda tam eşleşmeler nadiren gerçekleşir. Ancak x değerinden y değerine kadar bir olasılık yoğunluk işlevinin entegrasyonu, x ile y arasındaki veri örneklerinin beklenen sıklığını verir.
Örneğin, ortalaması 200 ve standart sapması 30 olan normal bir dağılımı ele alalım. 211,4 ile 218,7 aralığına giren veri örneklerinin beklenen sıklığını belirlemek için normal dağılımın olasılık yoğunluk işlevini 211,4 ile 218,7 arasında entegre edebilirsiniz.
R
Commonsense Reasoning Dataset (ReCoRD) ile Okuduğunu Anlama
Bir LLM'nin sağduyulu akıl yürütme yeteneğini değerlendirmek için kullanılan veri kümesi. Veri kümesindeki her örnek üç bileşen içerir:
- Bir haber makalesinden bir veya iki paragraf
- Geçitte açıkça veya dolaylı olarak tanımlanan varlıklardan birinin maskelendiği sorgu.
- Cevap (maskeye ait olan öğenin adı)
Kapsamlı örnek listesi için ReCoRD'a bakın.
ReCoRD, SuperGLUE topluluğunun bir bileşenidir.
RealToxicityPrompts
Zararlı içerik barındırabilecek bir dizi cümle başlangıcı içeren veri kümesi. Bu veri kümesini, LLM'nin cümleyi tamamlamak için zararlı olmayan metin oluşturma becerisini değerlendirmek için kullanın. Genellikle, LLM'nin bu görevdeki performansını belirlemek için Perspective API'yi kullanırsınız.
Ayrıntılar için RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models (RealToxicityPrompts: Dil Modellerinde Nöral Toksik Dejenerasyonu Değerlendirme) başlıklı makaleyi inceleyin.
hatırlanabilirlik
Aşağıdaki soruyu yanıtlayan sınıflandırma modelleri için bir metrik:
Kesin referans pozitif sınıf olduğunda model, tahminlerin yüzde kaçını doğru şekilde pozitif sınıf olarak tanımladı?
Formül şu şekildedir:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
Bu örnekte:
- Gerçek pozitif, modelin pozitif sınıfı doğru tahmin ettiği anlamına gelir.
- Yanlış negatif, modelin yanlışlıkla negatif sınıfı tahmin ettiği anlamına gelir.
Örneğin, modelinizin, temel doğrusu pozitif sınıf olan örnekler üzerinde 200 tahminde bulunduğunu varsayalım. Bu 200 tahminden:
- 180'i doğru pozitifti.
- 20'si yanlış negatif çıktı.
Bu durumda:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Daha fazla bilgi için Sınıflandırma: Doğruluk, geri çağırma, hassasiyet ve ilgili metrikler başlıklı makaleyi inceleyin.
k değerinde geri çağırma (recall@k)
Öğelerin sıralanmış (düzenli) listesini çıkaran sistemleri değerlendirmek için kullanılan bir metrik. k konumundaki hatırlama, döndürülen alakalı öğelerin toplam sayısı içindeki listede yer alan ilk k öğedeki alakalı öğelerin oranını tanımlar.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
k ile kontrastı ayarlayın.
Metin İçerme İlişkisini Tanıma (RTE)
Bir LLM'nin, bir hipotezin metin pasajından çıkarılıp çıkarılamayacağını (mantıksal olarak) belirleme becerisini değerlendirmek için kullanılan veri kümesi. Bir RTE değerlendirmesindeki her örnek üç bölümden oluşur:
- Genellikle haber veya Wikipedia makalelerinden alınan bir pasaj
- Hipotez
- Doğru yanıt, aşağıdakilerden biridir:
- Doğru (True): Hipotezin pasajdan çıkarılabileceği anlamına gelir.
- Yanlış. Yani hipotez, pasajdan çıkarılamaz.
Örneğin:
- Parça: Euro, Avrupa Birliği'nin para birimidir.
- Hipotez: Fransa'da para birimi olarak Euro kullanılır.
- İçerme: Fransa, Avrupa Birliği'nin bir parçası olduğundan doğru.
RTE, SuperGLUE topluluğunun bir bileşenidir.
ReCoRD
Reading Comprehension with Commonsense Reasoning Dataset (Mantıksal Akıl Yürütme Veri Kümesiyle Okuduğunu Anlama) ifadesinin kısaltması.
ROC (alıcı çalıştırma niteliği) eğrisi
İkili sınıflandırmada farklı sınıflandırma eşikleri için gerçek pozitif oranı ile yanlış pozitif oranı arasındaki ilişkiyi gösteren grafik.
ROC eğrisinin şekli, ikili sınıflandırma modelinin pozitif sınıfları negatif sınıflardan ayırma yeteneğini gösterir. Örneğin, ikili sınıflandırma modelinin tüm negatif sınıfları tüm pozitif sınıflardan mükemmel şekilde ayırdığını varsayalım:

Önceki modelin ROC eğrisi aşağıdaki gibi görünür:

Buna karşılık, aşağıdaki resimde, negatif sınıfları pozitif sınıflardan hiç ayıramayan kötü bir modelin ham lojistik regresyon değerleri grafik olarak gösterilmektedir:
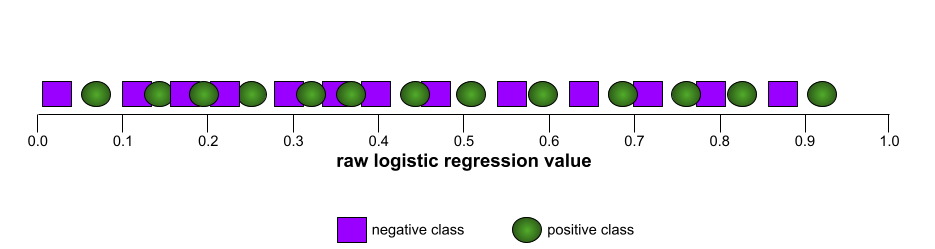
Bu modelin ROC eğrisi aşağıdaki gibi görünür:

Bu arada, gerçek hayatta çoğu ikili sınıflandırma modeli pozitif ve negatif sınıfları bir dereceye kadar ayırır ancak genellikle mükemmel bir şekilde değil. Bu nedenle, tipik bir ROC eğrisi iki uç nokta arasında bir yerde bulunur:
Bir ROC eğrisinde (0.0,1.0) noktasına en yakın olan nokta, teorik olarak ideal sınıflandırma eşiğini tanımlar. Ancak ideal sınıflandırma eşiğinin seçilmesini etkileyen başka gerçek dünya sorunları da vardır. Örneğin, yanlış negatif sonuçlar, yanlış pozitif sonuçlardan çok daha fazla sorun yaratabilir.
AUC adı verilen sayısal bir metrik, ROC eğrisini tek bir kayan nokta değeriyle özetler.
Kök Ortalama Kare Hatası (RMSE)
Ortalama karesel hatanın karekökü.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Otomatik özetleme ve makine çevirisi modellerini değerlendiren bir metrik ailesi. ROUGE metrikleri, referans metnin bir makine öğrenimi modelinin oluşturulan metniyle ne kadar örtüştüğünü belirler. ROUGE ailesinin her üyesi, çakışmayı farklı şekilde ölçer. ROUGE puanları ne kadar yüksek olursa referans metin ile oluşturulan metin arasındaki benzerlik o kadar fazla olur.
Her ROUGE ailesi üyesi genellikle aşağıdaki metrikleri oluşturur:
- Hassasiyet
- Geri çağırma
- F1
Ayrıntılar ve örnekler için:
ROUGE-L
ROUGE ailesinin bir üyesi, referans metin ve oluşturulan metindeki en uzun ortak alt dizinin uzunluğuna odaklanır. Aşağıdaki formüller, ROUGE-L için hatırlama ve kesinliği hesaplar:
Ardından, ROUGE-L recall ve ROUGE-L precision'ı tek bir metrikte toplamak için F1'i kullanabilirsiniz:
ROUGE-L, referans metin ve oluşturulan metindeki yeni satırları yok sayar. Bu nedenle, en uzun ortak alt dizi birden fazla cümleyi kapsayabilir. Referans metin ve oluşturulan metin birden fazla cümle içerdiğinde genellikle ROUGE-Lsum adı verilen ROUGE-L varyasyonu daha iyi bir metriktir. ROUGE-Lsum, bir pasajdaki her cümle için en uzun ortak alt diziyi belirler ve ardından bu en uzun ortak alt dizilerin ortalamasını hesaplar.
ROUGE-N
ROUGE ailesindeki bir dizi metrik, referans metin ve oluşturulan metindeki belirli boyuttaki ortak N-gramları karşılaştırır. Örneğin:
- ROUGE-1, referans metin ve oluşturulan metindeki ortak jeton sayısını ölçer.
- ROUGE-2, referans metin ve oluşturulan metindeki ortak bigram (2 gram) sayısını ölçer.
- ROUGE-3, referans metin ve oluşturulan metindeki ortak üçlü gram (3 gram) sayısını ölçer.
ROUGE-N ailesinin herhangi bir üyesi için ROUGE-N geri çağırma ve ROUGE-N kesinliğini hesaplamak üzere aşağıdaki formülleri kullanabilirsiniz:
Daha sonra, ROUGE-N geri çağırma ve ROUGE-N kesinliğini tek bir metrikte toplamak için F1'i kullanabilirsiniz:
ROUGE-S
ROUGE-N'nin, skip-gram eşleşmesine olanak tanıyan, daha esnek bir biçimidir. Yani ROUGE-N yalnızca tam olarak eşleşen N-gramları sayar ancak ROUGE-S, bir veya daha fazla kelimeyle ayrılmış N-gramları da sayar. Örneğin aşağıdakileri göz önünde bulundurabilirsiniz:
- referans metin: Beyaz bulutlar
- üretilen metin: Beyaz kabarık bulutlar
ROUGE-N hesaplanırken 2 gramlık Beyaz bulutlar, Beyaz kabarık bulutlar ile eşleşmiyor. Ancak ROUGE-S hesaplanırken Beyaz bulutlar, Beyaz kabarık bulutlar ile eşleşir.
R-kare
Bir etiketteki varyasyonun ne kadarının tek bir özellikten veya bir özellik grubundan kaynaklandığını gösteren regresyon metriği. Belirleme katsayısı, 0 ile 1 arasında bir değerdir ve şu şekilde yorumlanabilir:
- 0 R kare değeri, bir varyasyonun hiçbirinin özellik grubundan kaynaklanmadığı anlamına gelir.
- Belirleme katsayısının 1 olması, bir etiketin varyasyonunun tamamının özellik grubundan kaynaklandığı anlamına gelir.
- 0 ile 1 arasındaki bir R kare değeri, etiketin varyasyonunun belirli bir özellikten veya özellik grubundan ne ölçüde tahmin edilebileceğini gösterir. Örneğin, 0,10'luk bir R kare değeri, etiketteki varyansın yüzde 10'unun özellik kümesinden kaynaklandığı anlamına gelir. 0,20'lik bir R kare değeri, yüzde 20'sinin özellik kümesinden kaynaklandığı anlamına gelir.
Belirleme katsayısı, bir modelin tahmin ettiği değerler ile kesin referans arasındaki Pearson korelasyon katsayısının karesidir.
RTE
Recognizing Textual Entailment (Metin İçerme İlişkisini Tanıma) kısaltması.
G
puanlama
Öneri sisteminin, aday oluşturma aşamasında üretilen her öğe için bir değer veya sıralama sağlayan kısmı.
benzerlik ölçüsü
Kümeleme algoritmalarında, iki örneğin ne kadar benzer olduğunu belirlemek için kullanılan metrik.
seyreklik
Bir vektör veya matriste sıfır (ya da boş) olarak ayarlanan öğe sayısının, söz konusu vektör veya matristeki toplam giriş sayısına bölünmesiyle elde edilen değer. Örneğin, 98 hücresinde sıfır bulunan 100 öğeli bir matrisi ele alalım. Seyrekliği hesaplama şekli şöyledir:
Özellik seyrekliği, özellik vektörünün seyrekliğini ifade ederken model seyrekliği, model ağırlıklarının seyrekliğini ifade eder.
SQuAD
SQuAD: 100.000+ Questions for Machine Comprehension of Text (SQuAD: Metinlerin Makine Tarafından Anlaşılması İçin 100.000'den Fazla Soru) adlı makalede tanıtılan Stanford Question Answering Dataset (Stanford Soru-Cevap Veri Kümesi) kısaltması. Bu veri kümesindeki sorular, Wikipedia makaleleriyle ilgili sorular soran kullanıcılardan alınmıştır. SQuAD'daki bazı soruların yanıtları vardır ancak diğer soruların yanıtları kasıtlı olarak verilmemiştir. Bu nedenle, SQuAD'ı kullanarak bir LLM'nin aşağıdaki iki işlemi de yapabilme becerisini değerlendirebilirsiniz:
- Yanıtlanabilecek soruları yanıtlayın.
- Yanıtlanamayan soruları belirleyin.
Tam eşleme ile birlikte F1, SQuAD'a karşı LLM'leri değerlendirmek için en yaygın kullanılan metriklerdir.
kare menteşe kaybı
Menteşe kaybının karesi. Karesel menteşe kaybı, aykırı değerleri normal menteşe kaybına kıyasla daha sert şekilde cezalandırır.
kare kaybı
L2 kaybı ile eş anlamlıdır.
SuperGLUE
Bir LLM'nin metin anlama ve oluşturma konusundaki genel yeteneğini derecelendirmek için kullanılan bir veri kümesi topluluğu. Topluluk aşağıdaki veri kümelerinden oluşur:
- Boolean Questions (BoolQ)
- CommitmentBank (CB)
- Olası Alternatif Seçimi (COPA)
- Çok Cümleli Okuduğunu Anlama (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Recognizing Textual Entailment (RTE)
- Bağlamdaki Kelimeler (WiC)
- Winograd Schema Challenge (WSC)
Ayrıntılar için SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems (SuperGLUE: Genel Amaçlı Dil Anlama Sistemleri İçin Daha Yapışkan Bir Karşılaştırma) başlıklı makaleye göz atın.
T
test kaybı
Bir modelin test kümesine karşı kaybını temsil eden bir metrik. Model oluştururken genellikle test kaybını en aza indirmeye çalışırsınız. Bunun nedeni, düşük test kaybının düşük eğitim kaybı veya düşük doğrulama kaybından daha güçlü bir kalite sinyali olmasıdır.
Test kaybı ile eğitim kaybı veya doğrulama kaybı arasında büyük bir fark olması bazen düzenlileştirme oranını artırmanız gerektiğini gösterir.
top-k doğruluğu
Oluşturulan listelerin ilk k konumunda "hedef etiketin" görünme yüzdesi. Listeler, kişiselleştirilmiş öneriler veya softmax'a göre sıralanmış öğelerden oluşabilir.
Top-k doğruluğu, k'da doğruluk olarak da bilinir.
toksik
İçeriğin kötüye kullanım, tehdit veya rahatsız edici olma derecesi Birçok makine öğrenimi modeli, kötü niyetli davranışları tanımlayabilir, ölçebilir ve sınıflandırabilir. Bu modellerin çoğu, toksikliği birden fazla parametreye göre tanımlar. Örneğin, taciz edici dil seviyesi ve tehdit edici dil seviyesi.
eğitim kaybı
Belirli bir eğitim yinelemesi sırasında modelin kaybını temsil eden bir metrik. Örneğin, kayıp işlevinin ortalama karesel hata olduğunu varsayalım. Örneğin, 10.yinelemede eğitim kaybı (ortalama kare hatası) 2,2 ve 100.yinelemede eğitim kaybı 1,9 olabilir.
Kayıp eğrisi, eğitim kaybını yineleme sayısına karşı çizer. Bir kayıp eğrisi, eğitimle ilgili aşağıdaki ipuçlarını sağlar:
- Aşağı doğru eğim, modelin iyileştiğini gösterir.
- Yukarı doğru eğim, modelin kötüleştiğini gösterir.
- Düz bir eğim, modelin yakınsama noktasına ulaştığını gösterir.
Örneğin, aşağıdaki biraz idealize edilmiş kayıp eğrisi şunları gösterir:
- İlk yinelemeler sırasında hızlı model iyileştirmesini ifade eden dik bir aşağı eğim.
- Eğitimin sonuna yaklaşana kadar kademeli olarak düzleşen (ancak yine de aşağı doğru) bir eğim. Bu, modelin iyileşmeye devam ettiğini ancak ilk yinelemelerdeki hızdan biraz daha yavaş bir hızda iyileştiğini gösterir.
- Eğitimin sonuna doğru düz bir eğim, yakınsama olduğunu gösterir.

Eğitim kaybı önemli olsa da genelleme konusuna da göz atın.
Bilgi Yarışması Sorularını Yanıtlama
LLM'nin trivia sorularını yanıtlama becerisini değerlendirmek için kullanılan veri kümeleri. Her veri kümesi, bilgi yarışması meraklıları tarafından oluşturulan soru-cevap çiftlerini içerir. Farklı veri kümeleri, aşağıdakiler dahil olmak üzere farklı kaynaklara dayanır:
- Web araması (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Daha fazla bilgi için TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension (TriviaQA: Okuduğunu Anlama İçin Uzaktan Denetimli Büyük Ölçekli Bir Yarışma Veri Kümesi) başlıklı makaleyi inceleyin.
doğru negatif (TN)
Modelin negatif sınıfı doğru şekilde tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olmadığını çıkarır ve bu e-posta iletisi gerçekten spam değildir.
Gerçek pozitif (TP)
Modelin pozitif sınıfı doğru tahmin ettiği bir örnek. Örneğin, model belirli bir e-posta iletisinin spam olduğunu çıkarımlıyor ve bu e-posta iletisi gerçekten spam oluyor.
Gerçek pozitif oranı (TPR)
Geri çağırma ile eş anlamlıdır. Yani:
Gerçek pozitif oranı, ROC eğrisindeki y eksenidir.
Typologically Diverse Question Answering (TyDi QA)
LLM'nin soruları yanıtlama yeterliliğini değerlendirmek için kullanılan büyük bir veri kümesi. Veri kümesi, birçok dilde soru ve cevap çiftleri içerir.
Ayrıntılı bilgi için TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages (TyDi QA: Farklı Dil Gruplarındaki Bilgi Arayışına Yönelik Soru-Cevap İçin Bir Karşılaştırma) başlıklı makaleyi inceleyin.
V
doğrulama kaybı
Eğitimin belirli bir iterasyonu sırasında doğrulama kümesindeki bir modelin kaybını temsil eden bir metrik.
Ayrıca genelleştirme eğrisini de inceleyin.
değişken önemleri
Her bir özelliğin model için göreli önemini gösteren bir puan grubu.
Örneğin, ev fiyatlarını tahmin eden bir karar ağacını ele alalım. Bu karar ağacının üç özellik kullandığını varsayalım: boyut, yaş ve stil. Üç özellik için değişken önem düzeyleri kümesi {size=5.8, age=2.5, style=4.7} olarak hesaplanırsa boyut, karar ağacı için yaş veya stilden daha önemlidir.
Farklı değişken önem metrikleri vardır. Bu metrikler, makine öğrenimi uzmanlarını modellerin farklı yönleri hakkında bilgilendirebilir.
W
Wasserstein kaybı
Üretilen verilerin dağıtımı ile gerçek veriler arasındaki toprak taşıyıcının mesafesine dayalı olarak üretken çekişmeli ağlarda yaygın olarak kullanılan kayıp işlevlerinden biridir.
WiC
Words in Context (Bağlamdaki Kelimeler) için kısaltma.
WikiLingua (wiki_lingua)
LLM'nin kısa makaleleri özetleme becerisini değerlendirmek için kullanılan bir veri kümesi. Çeşitli görevlerin nasıl yapılacağını açıklayan makalelerden oluşan bir ansiklopedi olan WikiHow, hem makalelerin hem de özetlerin insan tarafından yazılmış kaynağıdır. Veri kümesindeki her giriş şunlardan oluşur:
- Numaralı listenin düz yazı (paragraf) sürümündeki her adımın, her adımın açılış cümlesi hariç eklenmesiyle oluşturulan bir makale.
- Numaralı listedeki her adımın ilk cümlesinden oluşan makale özeti.
Ayrıntılar için WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization (WikiLingua: Diller Arası Özetleyici Özetleme İçin Yeni Bir Karşılaştırma Veri Kümesi) başlıklı makaleyi inceleyin.
Winograd Şeması Yarışması (WSC)
Bir LLM'nin, zamirin atıfta bulunduğu isim öbeğini belirleme becerisini değerlendirmek için kullanılan bir biçim (veya bu biçime uygun bir veri kümesi).
Bir Winograd Şema Yarışması'ndaki her giriş şunlardan oluşur:
- Hedef zamiri içeren kısa bir pasaj
- Hedef zamir
- Aday isim öbekleri ve ardından doğru yanıt (Boole) Hedef zamir bu adayı ifade ediyorsa yanıt Doğru'dur. Hedef zamir bu adayı ifade etmiyorsa yanıt Yanlış'tır.
Örneğin:
- Parça: Mark, Pete'e kendisi hakkında birçok yalan söyledi. Pete de bu yalanları kitabına ekledi. Daha dürüst olmalıydı.
- Hedef zamir: O (Erkek)
- Aday isim öbekleri:
- Mark: Doğru, çünkü hedef zamir Mark'ı ifade ediyor.
- Ali: Yanlış, çünkü hedef zamir Ali'yi ifade etmiyor.
Winograd Şeması Yarışması, SuperGLUE topluluğunun bir bileşenidir.
Bağlamdaki Kelimeler (WiC)
Bir LLM'nin, birden fazla anlamı olan kelimeleri anlamak için bağlamı ne kadar iyi kullandığını değerlendirmeye yönelik bir veri kümesi. Veri kümesindeki her giriş şunları içerir:
- Her biri hedef kelimeyi içeren iki cümle
- Hedef kelime
- Doğru yanıt (Boole değeri), burada:
- Doğru, hedef kelimenin iki cümlede de aynı anlama geldiği anlamına gelir.
- Yanlış, hedef kelimenin iki cümlede farklı anlamlara geldiğini gösterir.
Örneğin:
- İki cümle:
- Nehir yatağında çok fazla çöp var.
- Uyurken yatağımın yanında bir bardak su bulundururum.
- Hedef kelime: yatak
- Doğru yanıt: Yanlış, çünkü hedef kelime iki cümlede farklı anlamlara geliyor.
Ayrıntılar için WiC: Bağlama Duyarlı Anlam Gösterimlerini Değerlendirmek İçin Bağlamdaki Kelime Veri Kümesi başlıklı makaleyi inceleyin.
Bağlamdaki Kelimeler, SuperGLUE topluluğunun bir bileşenidir.
WSC
Winograd Şema Yarışması'nın kısaltması.
X
XL-Sum (xlsum)
Bir LLM'nin metin özetleme yeterliliğini değerlendirmek için kullanılan veri kümesi. XL-Sum, birçok dilde girişler sağlar. Veri kümesindeki her giriş şunları içerir:
- British Broadcasting Company'den (BBC) alınmış bir makale.
- Makalenin yazarı tarafından yazılan makale özeti. Özetin, makalede yer almayan kelimeler veya ifadeler içerebileceğini unutmayın.
Ayrıntılı bilgi için XL-Sum: 44 Dilde Büyük Ölçekli Çok Dilli Özetleyici Özetleme başlıklı makaleyi inceleyin.